legacy-wiki
Cloud
Recovered from the older tannerjc.net wiki snapshot dated January 23, 2016.
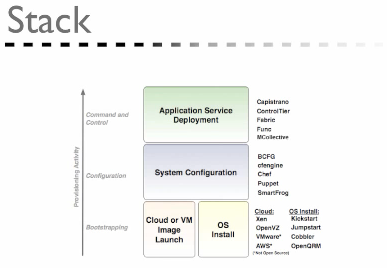
layers
- http://en.wikipedia.org/wiki/Cloud_computing
- client
- application
- platform
- infrastructure
- server
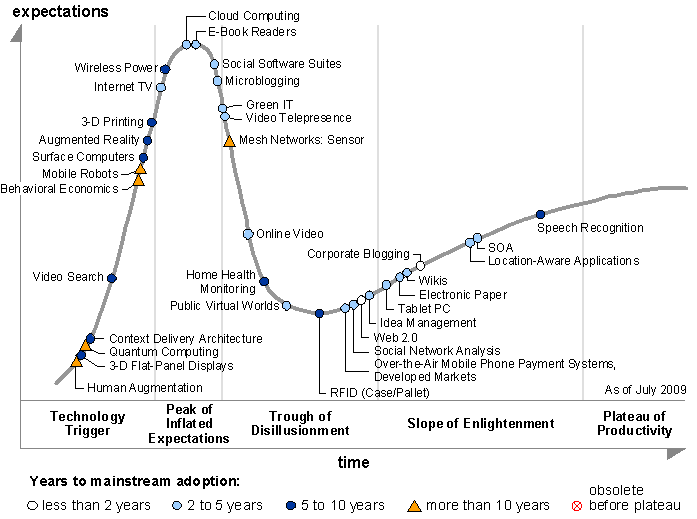
hype
- http://www.gartner.com/it/page.jsp?id=1124212
- This Hype Cycle features technologies that are the focus of attention in the IT industry because of particularly high levels of hype, or those that may not be broadly acknowledged but which Gartner believes have the potential for significant impact.
orchestration
configuration
-
http://www.ittechnewsdaily.com/178-avoiding-cloud-problems.html
-
Automation discipline
-
Version control
-
Hybrid approach
-
Model-driven configuration
-
http://www.dre.vanderbilt.edu/~schmidt/PDF/IGIChapterProposal-Dougherty.pdf
-
http://w3.isis.vanderbilt.edu/Projects/gme/meta.html MetaGME
-
Tightly constrained parameterization
-
http://people.byte-code.com/fcrippa/wp-content/uploads/2008/06/fcrippa_large-scale-env.pdf
-
‘The complexity is not on the “business”, but on the “infrastructure
model driven configuration
-
http://www.dre.vanderbilt.edu/~schmidt/PDF/IGIChapterProposal-Dougherty.pdf
-
http://w3.isis.vanderbilt.edu/Projects/gme/meta.html MetaGME
-
http://www.dre.vanderbilt.edu/~schmidt/PDF/FireAnt-poster-paper.pdf
-
http://www.dre.vanderbilt.edu/~schmidt/PDF/FireAnt_Models.pdf
blockquote Challenge 2 - Managing the complexity of hundreds of valid configuration and deployment options for product line variants. Ad hoc techniques often employ build and configuration tools, such as Make and Another Neat Tool (ANT) [6], but application deployers still must manage the large number of scripts required to perform the component installations. Developing these scripts can involve significant effort and require in-depth understanding of components. Understanding these intricacies and properly configuring applications is crucial to their proper functionality and quality of service (QoS) requirements [7]. Incorrect system configuration due to operator error has also been shown to be a significant contributor to down-time and recovery [5]. Developing custom deployment and configuration scripts for each variant leads to a significant amount of reinvention and rediscovery of common deployment and configuration processes. As the number of valid variants increases, there is a corresponding rise in the complexity of developing and maintaining each variant’s deployment and configuration infrastructure. Automated techniques can be used to manage this complexity [8,9,10]. /blockquote
blockquote Challenge 4 - Ensuring that a PLA is rigorously tested in all valid configurations. Even when model-driven development (MDD) [11] techniques and tools, are used to generate the customization, composition, packaging, and deployment code to implement PLA variants [9, 12] it is still impossible to ensure that all correctly constructed variants will perform as modeled. In mission-critical domains, such as avionics and automotive systems, it is essential that nonfunctional variants be discovered. The large number of valid variants, however, makes it hard to test all the valid con-figurations and deployments. Rapid regression testing in response to component changes is even harder. /blockquote
-
http://devops.com/2011/06/07/orbitz-ideas-puppet-config-management/
-
model driven systems management blockquote managing images isn’t good enough. can’t have black box images with thousands and thousands of nodes. need to be able to have composable configuration. have sub roles and compose them different ways like legos. /blockquote
-
https://groups.google.com/group/puppet-users/browse_thread/thread/95b6625f30c25f53?pli=1 blockquote Rolling back files is not hard, but once you get to something like packages, you are depending on the packages themselves to do the right thing, and that is not always prudent. FYI, in my personal opinion, implementing rollback is probably more effort than it is worth. Difficult to get right and I don’t see the ROI versus a reasonable dev, test, staging, production approach that lets you deploy with confidence. Call it a ‘roll forward’ strategy. /blockquote
blockquote Second, when using both rPath and Puppet, it makes sense to focus Puppet on its core strength — managing configuration settings — not on installing software updates. rPath is a stronger package manager and patch manager thanks to full rollback, versioning, and dependency resolution. /blockquote
blockquote When you configure the application via a Puppet manifest, and deliver that manifest and the application update with rPath, they stay perfectly synchronized (for rollout and rollback) and are delivered as a unit. /blockquote
blockquote Puppet, Cfengine, and Chef solve this problem with specialized syntax in their scripting languages. You use Boolean criteria on system properties, pattern matching, and lists of server names to identify which configurations to apply to which systems. This approach becomes complex and brittle when you scale to many classes of systems. /blockquote
blockquote We believe in parameterizing deployable components in specific ways instead of trying to discover and control every last knob on a system. If you look at a random Linux box running a 3-tier app, there are thousands of individual config settings scattered throughout the stack. But the vast majority of those are static and have sensible defaults. When architects talk about deployment, they call out the tweakable bits they care about—addresses, port numbers, database names and the like. /blockquote
-
http://blogs.rpath.com/wpmu/technically-speaking/2011/04/04/peeling-the-config-onion-with-rpath/
-
Config editing—The domain-specific, parameterized methods of actually changing configuration settings. How do I alter the port number in httpd.conf?
-
Control—Layer 2 is about providing the right parameters to layer 1 and controlling the process.
-
Group—Groups of heterogeneous systems—running different operating systems, middleware stacks, and applications—often need common configuration parameters due to their group membership. rPath X6 includes system sets, which are flexible, hierarchical grouping mechanisms for managing deployed systems.
-
Multi-tier—Finally, we have the problem of configuring different components of a complex service (intra- and inter-server) to talk to each other.
blockquote services we studied all use redundancy in an attempt to mask component failures. That is, they try to prevent component failures from turning into end-user visible failures. As indicated by Figure 4 and Figure 5, this technique generally does a good job of preventing hardware, software, and network component failures from turning into service failures, but it is much less effective at masking operator failures. A qualitative analysis of the failure data suggests that this is because operator actions tend to be performed on files that affect the operation of the entire service or of a partition of the service, e.g., configuration files or content files. /blockquote
blockquote Fully half of the 36 operator errors resulted in service failure, suggesting that operator errors are significantly more difficult to mask using the service’s existing redundancy mechanism /blockquote
blockquote Apparently more expensive hardware isn’t always more reliable. /blockquote
blockquote Table 2 shows that contrary to conventional wisdom, front-end machines are a significant source of failure–in fact, they are responsible for more than half of the service failures in Online and Content. This fact was largely due to operator configuration errors at the application or operating system level. Almost all of the problems in ReadMostly were network-related; we attribute this to simpler and better-tested application software at that service, fewer changes made to the service on a day-to-day basis, and a higher degree of node redundancy than is used at Online and Content /blockquote
blockquote Operator error in all three services generally took the form of misconfiguration rather than procedural errors (e.g., moving a user to the wrong fileserver). /blockquote
blockquote Indeed, for all three services, more than 50% (and in one case nearly 100%) of the operator errors that led to service failures were configuration errors. In general, operator errors arose when operators were making changes to the system, e.g., scaling or replacing hardware, or deploying or upgrading software. /blockquote
blockquote From Table 6 we observe that online testing would have helped the most, mitigating 26 service failures. The second most helpful technique, more thoroughly exposing and monitoring for software and hardware failures, would have decreased TTR and/or TTD in more than 10 instances. Simply increasing redundancy would have mitigated 9 failures. Automatic sanity checking of configuration files, and online fault and load injection, also appear to offer significant potential benefit /blockquote
blockquote The operator accidentally configured that email server not to run the lookup daemon because he or she did not realize that proper operation of that mail server depended on its running that daemon. /blockquote
blockquote operators need to understand the high-level dependencies and interactions among the software modules that comprise a service. Online testing would have detected this problem, while better exposing failures, and improved techniques for diagnosing failures, would have decreased the time needed to detect and localize this problem. Online regression testing should take place not only after changes to software components, but also after changes to system configuration /blockquote
blockquote operator error is the most difficult component failure to mask through traditional techniques. Industry has paid a great deal of attention to the end-user experience, but has neglected tools and systems used by operators for configuration, monitoring, diagnosis, and repair /blockquote
blockquote the majority of operator errors leading to service failure were misconfigurations. /blockquote
blockquote Several techniques could improve this situation. One is improved operator interfaces. This does not mean a simple GUI wrapper around existing per-component command-line configuration mechanisms–we need fundamental advances in tools to help operators understand existing system configuration and component dependencies, and how their changes to one component’s configuration will affect the service as a whole. Tools to help visualize existing system configuration and dependencies would have averted some operator errors (configuration-related and otherwise) by ensuring that an operator’s mental model of the existing system configuration matched the true configuration. /blockquote
blockquote Another approach is to build tools that do for configuration files what lint [8] does for C programs: to check configuration files against known constraints. Such tools can be built incrementally, with support for additional types of configuration files and constraints added over time. This idea can be extended in two ways. First, support can be added for user-defined constraints, taking the form of a high-level specification of desired system configuration and behavior, much as [3] can be viewed as a user-extensible version of lint. Second, a high-level specification can be used to automatically generate per-component configuration files. /blockquote
blockquote Unfortunately there are no widely used generic tools to allow an operator to specify in a high-level way the desired service architecture and behavior, such that the specification could be checked against the existing configuration, or per-component configurations could be generated. Thus the very wide configuration interface remains error-prone /blockquote
blockquote A tool that, in a structured way, expresses the history of a system–including configuration and system state before and after each change, who or what made the change, why they made the change, and exactly what changes they made–would help operators understand how a problem evolved, thereby aiding diagnosis and repair /blockquote
blockquote the systems and tools operators use to administer services are not just primitive and difficult to use, they are also brittle. /blockquote
blockquote we observe that (1) operator error is the leading cause of failure in two of the three services studied, (2) operator error is the largest contributor to time to repair in two of the three services, (3) configuration errors are the largest category of operator errors, (4) failures in custom-written front-end software are significant, and (5) more extensive online testing and more thoroughly exposing and detecting component failures would reduce failure rates in at least one service. /blockquote
blockquote DRE system developers need to configure and tune the performance of the ACE+TAO+CIAO middleware at multiple levels, including lower-level messaging and transport mechanisms, the object request broker (ORB) itself, up to higher-level middleware services (such as event notification, scheduling, and load balancing). This problem is exacerbated by the fact that not all combinations of options form a semantically compatible set /blockquote
blockquote Unfortunately, the settings that maximize performance for a particular group of platforms and applications may not be suitable for different one /blockquote
remote control
log analysis
notes
nilsson XenServer requires a nova-compute domU to run on the hypervisor
in order to inject images into the VHDs. Nova-compute is the worker for the
Hypervisor. It pulls jobs and applies them to the hypervisor it resides on.
It's required to run on the hypervisor because it utilizes /sys/hypervisor.
nilsson http://wiki.openstack.org/XenServerDevelopment#Getting_Started_Notes
nilsson can someone explain to me why the XenServerDevelopment page instructs
you to install nova-compute on a DomU, rather than the Dom0 ?
jtanner nilsson, did you figure out why the XenServerDevelopment page instructs
you to install nova-compute on a DomU ?
nilsson jtanner, someone in ##xen mentioned that the dom0 should be as small as possible
nilsson with no extra services running
Bobo Thanks mate. I have alot of begginers questions. If I understood it corectly,
openstack is a sort of virtualisation like Xen, vServer etc..
* jmckenty_ (~joshuamck@c-24-4-68-181.hsd1.ca.comcast.net) has joined #openstack
pvo Bobo: no, openstack is the coordination of those hypervisors
pvo Bobo: it support many of them, but isn't a hypervisor itself.
* npmapn has quit (Ping timeout: 252 seconds)
Bobo Oh, so it is used to control xen and the others?
pvo Bobo: exactly
Articles
- http://natishalom.typepad.com/nati_shaloms_blog/2011/04/paas-on-openstack.html
- The main goal of PaaS is to drive productivity into the process by which we can deliver new applications.
- Most of the existing PaaS solutions take a fairly extreme approach with their abstraction of the underlying infrastructure and therefore fit a fairly small number of extremely simple applications and thus miss the real promise of PaaS.
- http://natishalom.typepad.com/nati_shaloms_blog/2011/05/citrix-openstack.html
- most enterprises don’t have the skills or the time to go through the process of building their own cloud from the source. These organizations would need a pre-packaged version of OpenStack that comes with built-in support, production management tools etc.
- Citrix certified version of OpenStack is geared specifically for [pre-packaged Openstack w/ support]